¿Qué datos necesitamos para este proyecto?
Necesitamos la mayor cantidad de letras de canciones posibles de un mismo cantante. Estos datos servirán como base para entrenar el modelo de Machine Learning que generará las nuevas letras.
¿De dónde los vamos a sacar?
Los datos los vamos a obtener de Genius. Este sitio web es muy popular porque puedes encontrar casi todo el catálogo de canciones (y letras) de un artista.
¿Cómo los vamos a obtener?
Vamos a utilizar el API de Genius para obtener la lista de canciones. Adicional, usaremos esta misma API para obtener los links desde dónde podemos ver la letra de la canción.
Ya que tengamos esta lista vamos a hacer web scrapping utilizando la librería de html-requests para obtener las letras.Para todo este proceso utilizaremos Python y Jupyter Notebook.
Nota: Hacer la configuración de los Jupyter Notebooks e importar las librerías de Python puede llegar a ser tardado. Si quieres comenzar rápidamente con este proyecto te recomiendo que uses Google Colab. Esta plataforma de Google te permite usar notebooks muy parecidos a los de Jupyter. Colab también te da acceso a cierto número de GPU’s. Todo esto sin tener que configurar absolutamente nada.
Resumen:
- 1. Crear una cuenta en Genius. Lo puedes hacer desde aqui.
- 2. Una vez que tengas tu cuenta, visita la página de Desarrolladores y da clic en Create an API Client
- 3. La página te solicitará que registres una app. Para el propósito de este proyecto, no vamos a requerir autentificar usuarios, por lo que puedes colocar la información que quieras.
- 4. Una vez agregada, la página te dará la opción de generar un Client Access Token. Genéralo y copialo.
- 5.Dentro de tu notebook Crea una variable que se llame
client_access_tokeny pega la información que copiaste como un string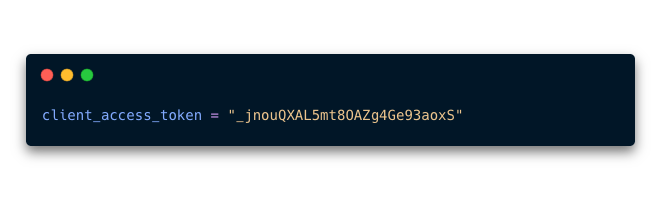
- 6. Importa las librerias
urlencode,requests,enocdeypandasa tu notebook. Las vamos a necesitar para utilizar el API de Genius.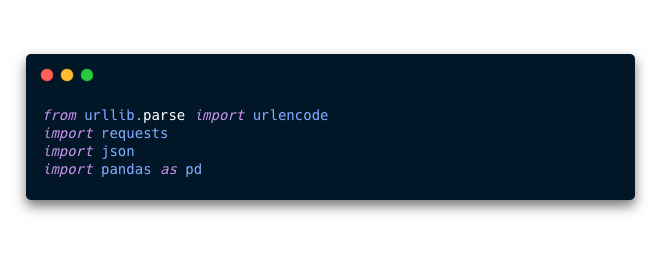
- 7. Crear una variable que se llame
headers. En esta variable se guardará un diccionario con unkeyque se llame “Authorization” y un fstring que tenga un valorBearer {client_access_token}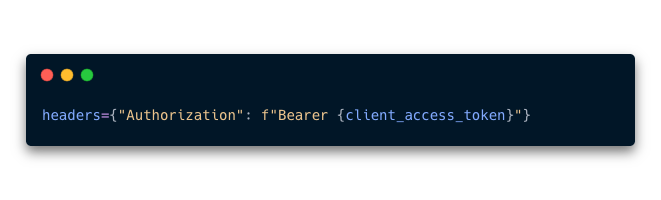
- 8. Con esta API puedes obtener mucha información acerca de tus artistas favoritos. Nosotros estamos interesados en obtener todo su catálogo de canciones. Para hacer esto vamos a utilizar 3 recursos de esta API.
Search,ArtistsySongs- 8.1
Search: Para obtener todas las canciones necesitamos un parametro llamadoid. Cada artista tiene uno distinto. Este parametro lo obtenemos llamando el recursoSearchy buscando elkeycon el nombreid. - 8.2 Para facilitar el proceso realice una función llamada
search_artist_idque acepta un parametro (search_term). Este parametro es el nombre del artista del cuál queremos elid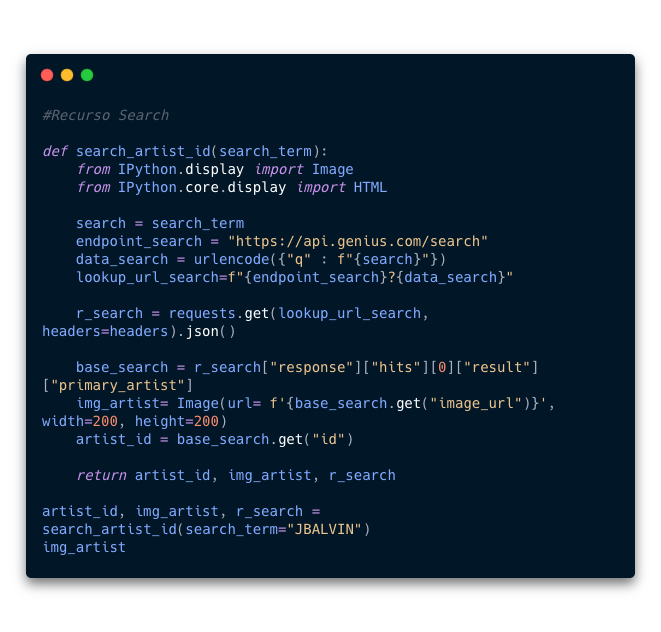
- 8.3 Ya que tenemos el
iddel artista, podemos obtener una lista de todas sus canciones. Para hacerlo usaremos el recursoSongs. - 8.4 De igual forma, para facilitar el proceso, genere una función llamada
all_artist_songsque acepta como parametro eliddel artista. Esta función nos regresa 2 resultadosfull_dfque contiene un dataframe con todas las canciones en las cuáles el artista principal tiene presencia (como vocalista, colaboración, productor, etc) yfull_df_cleanque contiene un dataframe con las canciones que interpreta el artista principalmente.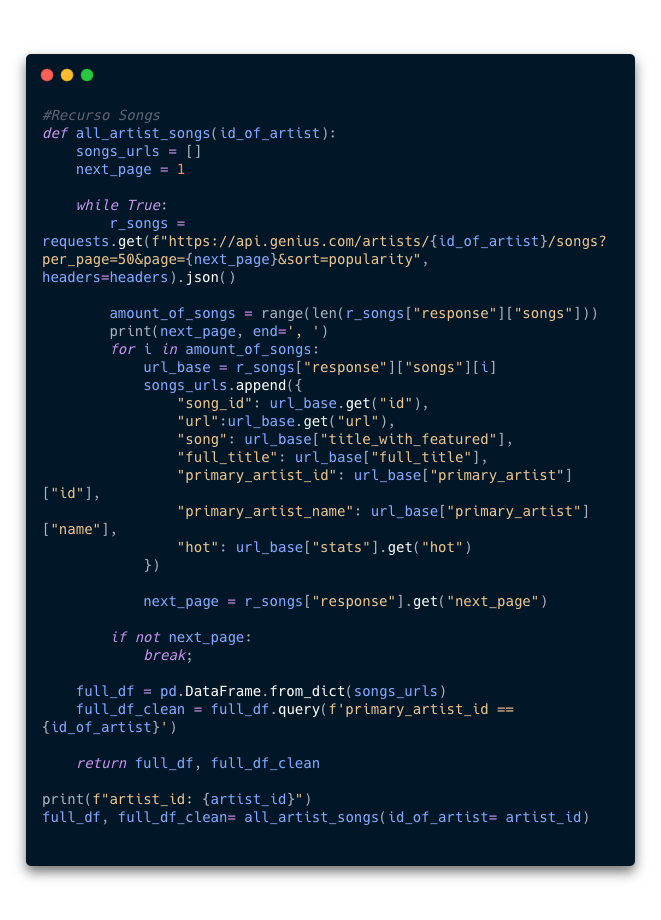
- 8.1
- 9. El ultimo paso del proceso es utilizar la libreria
requests_htmlpara obtener las letras de las canciones. Para esta parte del proceo vamos a hacer web_scraping. Es importante mencionar que este proceso puede ser completamente distinto al momento en el que estes viendo este tutorial. Esto ocurre debido a que dependemos enteramente de como esta organizado el HTML del sitio web.
- 9.1 Si quieres saber más acerca de esta librería, puedes hacerlo visitando su sito aqui
- 9.2 Para conocer más acerca de Web Scrapping y sus implicaciones, te recomiendo leer este artículo de Medium.
- 9.3 Ahora creamos una función llamada
words_from_song(url)que acepta como parametro unaurlde Genius que contenga la letra de una canción. En resumen esta función abrira la url, buscará la letra de la canción, la copiara y la dividira en oraciones. Estas oraciones serán la data que usaremos para entrenar nuestro modelo de Machine Learning.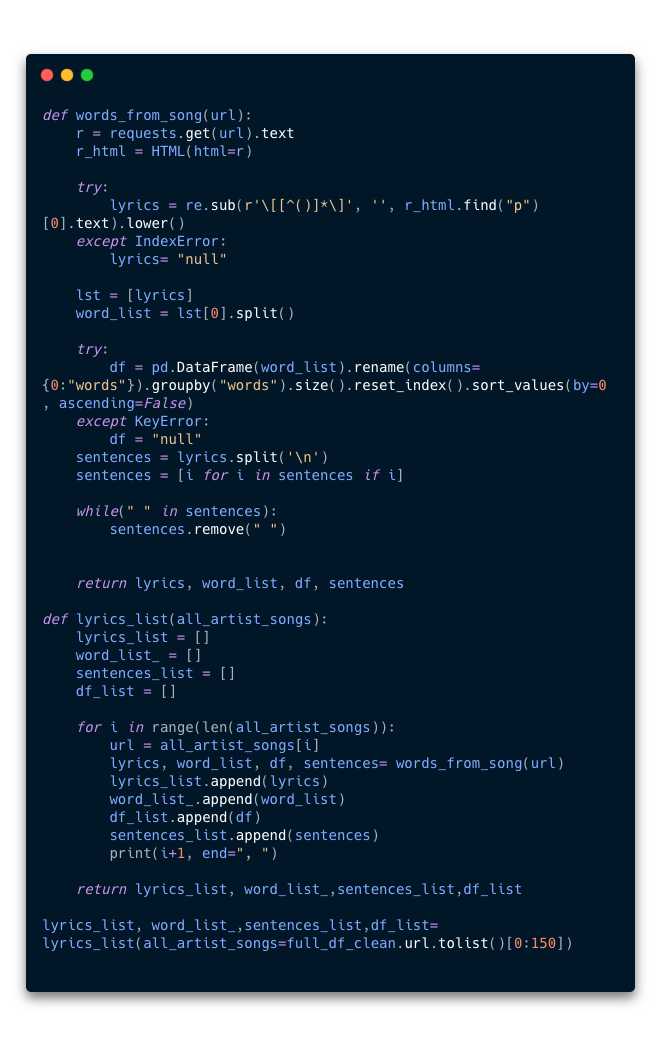
- 9.4 Ya que tenemos nuestra data dividida en oraciones, creamos una función llamada
combine_all_sentences()que acepta como parametro la lista de oraciones que genero la funciónwords_from_song(). Esta función nos va a regresar todas las oraciones combinadas en una sola lista.
- 9.5 Como ultimo paso vamos a exportar las canciones a formato txt. Para hacer esto creamos una función llamada
save_to_txt()que acepta como parametro las lista de oraciones que genero la funcióncombine_all_sentences(). Esta función genera el txt y lo guarda dónde le especifiquemos.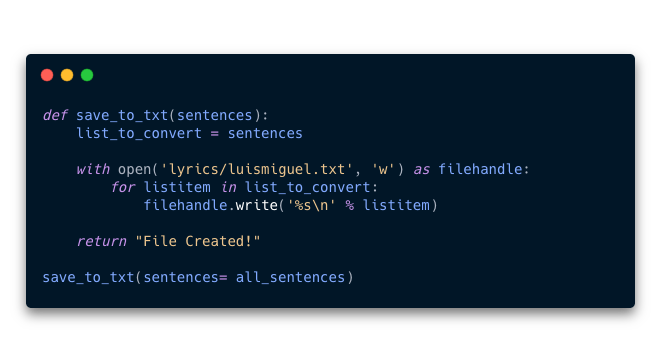
¡Listo!, ahora tenemos las letras de todas las canciones en un formato que podrá consumir nuestro modelo de Machine Learning.
Para que conozcas como construir el modelo y entrenarlo, te invito a que visites la parte 2 de este proyecto dando click aquí.
Visita mi repo en Github, en dónde podrás descargar el código de este proyecto, dando click aqui.