Spotify is probably the biggest music streaming platform in the world. One of the coolest things about it, is that it offers a robust API ecosystem that gives access to a lot of interesting data.
After learning some of the key concepts about this API, I decided to do a data analysis project using it. The main focus of this project was to analyze the music profiles from different countries and predict in which of this regions a new song could be succesful.
To accomplish this, I created a dataframe with all the songs that were associated with some of the most popular playlists per country. Once I got those songs I used the Spotify Audio Features function on each song and, as the last step, I used a Machine Learning model using those song features as my predictors.
I want to use this post to explain how I did this project and share some insights about the data that I saw.
You can visit my Github repo to check and download the code that I’m going to explain below.
1. Getting the data
All this project was created using Python in a Jupyter Notebook. Here are the basic libraries that I imported to the notebook.

1.1 The Spotify API
To kick off this project I read the Quick Start Guide that Spotify offers. That article is great because it explains how their API works and gives tons of examples.
Spotify offers several flavors of their API. For this project, I used the Web API. I enjoyed working with this version of the API because it gave me the possibility of testing different methods on a console.
To get access to that particular platform, I created a new app inside their developer platform. Access to this platform is through the use of a simple Spotify Account. You can click here to learn more about it.
Once the app is created you can get a Client_ID and a Client_Secret. The combination of these two strings creates an access_token which is necessary to use the API from the Jupyter Notebook.
Notes:
-
To navigate the Spotify API one key aspect that you need to always keep in mind is that everything works with “Spotify Unique ids”. Each song, album, artists, show, playlist, episode, etc. has a unique id.
-
For this project first I collected the individual ids of some playlists. Then I collected the ids of the tracks that composed that playlist and finally, based on the ids of those tracks, I got their features.
1.2 Helper Functions
For this project I created a series of Python “helper functions”. The purpose of these functions was to interact in a more efficient way with the Spotify API.
Here’s how I imported those functions:
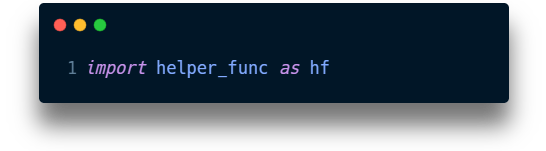
And here’s a brief description of the functions:
auth(): This functions generates theaccess_tokenby requesting theClient_IDand theClient_Secret. This token is important because it’s the key to use all the functionalities of the API.playlist_data(): This function returns a dataframe with key data about a particular playlist.song_features(): This function returns a dataframe with the features that Spotify assigns to each song.top_playlists():This function accepts a python list of countries as parameters and returns a dataframe with the top playlists from those countries.get_songs_from_recommended_playlists(): This function accepts a python list with “playlists ids” and returns a dataframe with the main information about those playlists.
1.3 Creating dataframes
Now we have the neccesary functions to start creating our dataframes. As mentioned at the beggining of this notebook, we want to get a sample of songs from different countries and analyze the charactersitics of those songs. Creating this dataframe is going to be a 3 step process:
- Get 10 playlists from each country. This will create a robust sample dataframe.
- Get all the songs from those playlists and create a dataframe with them.
- Once we have the dataframe with all of our songs, we add the features to them.
1.3.1 Creating our Access Token
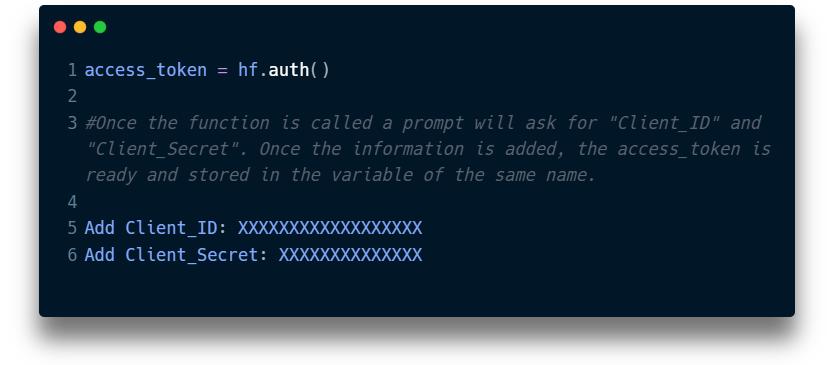
To create and handle the “Access Token” I created a function called auth(). When called, the function will ask for a Client_ID and a Client_Secret. You can learn how to get those access in this article.
Here’s and example of how I called the function:
Notes:
- Here you can find the article in which Spotify explains how the
access tokenworks. In addition, it also mentions different workflows that can be followed in order to get the token.
1.3.2 Getting the playlists
Spotify has an API call that gathers the top playlists per country. There’s a function inside our hf library called top_playlists() which accepts a list of countries as parameters and returns a dataframe with the top playlists from those countries.
Here’s an example of how I called the function:

And here’s an example of the returned dataframe:

1.3.3 Getting the songs from each playlist
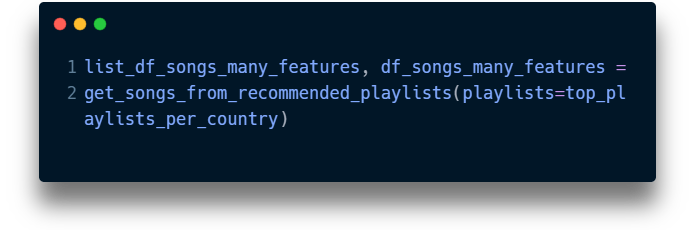
Now that we have our top playlists per country, we can get the songs that are inside that playlist. We can call the get_songs_from_recommended_playlists() to return the songs in a dataframe.
Here’s an example of how I called the function:
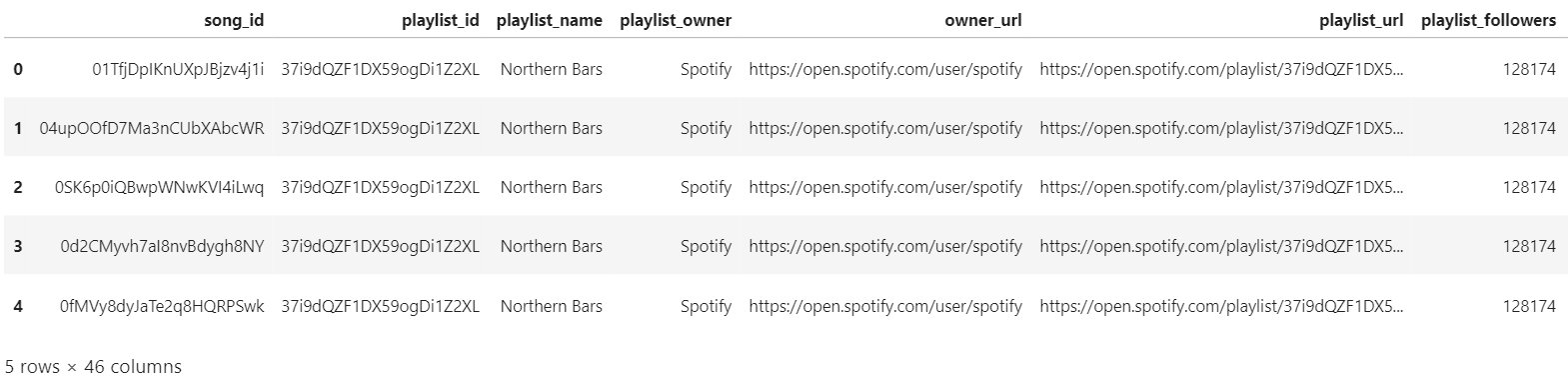
And here’s an example of the returned dataframe:
1.3.4 Adding features to each song.
Now that we have all the songs from each playlist, we can use the song_features() function to add their features.
Here’s how I call the function:
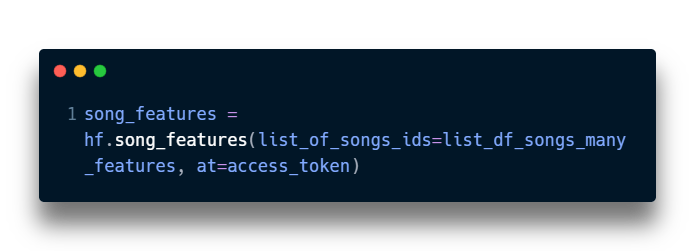
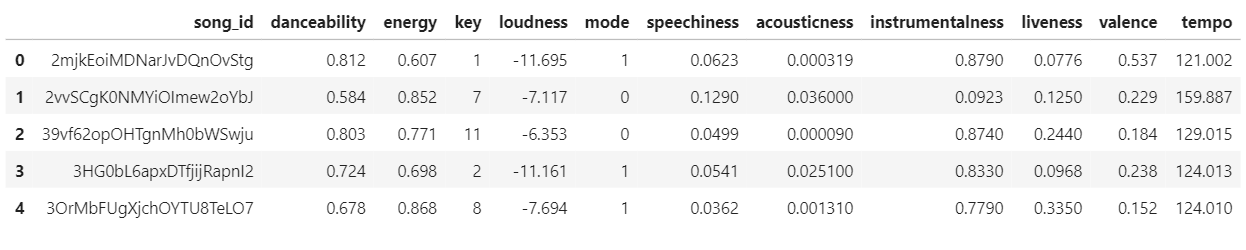
And here’s an example of the returned dataframe:
1.3.5 Merging the dataframes.
As a las step I merged the song features with my playlists information.
Here’s how I did the merge:
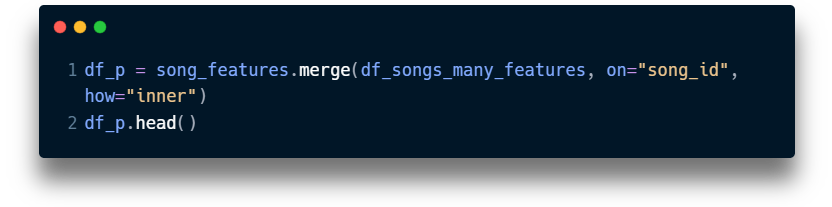
And here’s an example of the returned dataframe:

Next Steps
This was the first part of the project. Now that the dataframe is finished, we can proceed to do all the data analysis.
Click here to check the second part of this project.